How the Generic Recognition Set of Steps Work
The Generic Recognition set of steps gives the script writer access to more control over speech recognition capability than the Simple Recognition step.
The input part of the Generic Recognition step uses a general purpose grammar: The Generic Recognition step performs recognition based on the rules of the grammar specified in the step.
-
The Generic Recognition step uses the grammar to recognize the utterance provided by a user. It puts the result of this recognition into a result collection. The step assigns a name to the result collection. This name is used by the other steps to access this result collection.
-
The Get Recognition Interpretation step is used to select a specific result from the result collection.
-
The Get Recognition Interpretation step is used to select a specific interpretation within a specific result. The selected interpretation may have one or more slots as specified in the grammar. These slots contain information associated with this particular interpretation that give meaning to the recognition. For instance, if the recognized string was the name of a person from a company directory, there may be a slot in the interpretation called "extension" that contains the actual extension for that person. Another slot might contain the name of that person.
Slots are optional. Not all interpretations in the same result have to have the same slots (Although it is best to design the grammar so that slots are returned in a consistent manner).
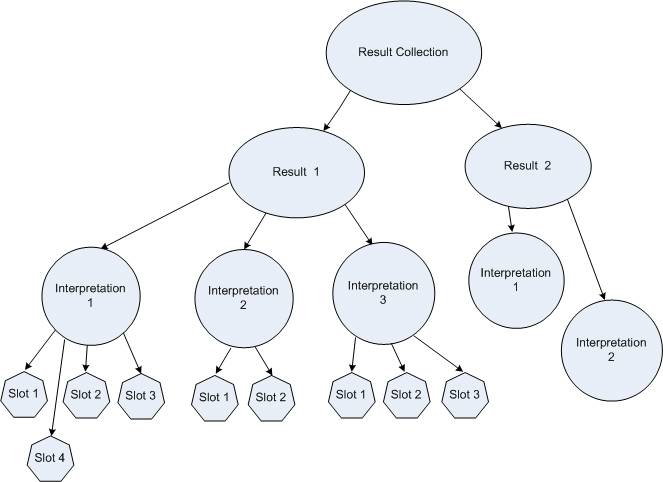
The Result Collection returned by the Generic Recognition Step can contain one or more Result. Each result differs from the other results in that their utterance and confidence level will not be the same. This will typically happen when two or more phrases in the grammar sound very similar but are in fact different words.
This could happen, for example, if the grammar contained separate recognition phrases of, say, "fog", "dog" and "frog".
If the speaker says "fog," the recognizer may actually also match the other two phrases as well. The difference is that the confidence level for the others will be lower than the confidence level for "fog". The confidence level for "fog" will probably be above 90 because it is a very close match to the word "fog" in the grammar. Note that "fog" will be the utterance for this result.
The result for "frog" may have a confidence level somewhere around 50 or 60. This is not a good match, but it will probably exceed the normal confidence threshold.
Finally the result for "dog" will probably have a confidence level much less than 50. It may not actually be returned in the result collection at all because the default confidence threshold is usually around 50.
Within each result there may be one or more interpretations. Multiple interpretations are possible when an ambiguous grammar is used. An ambiguous grammar is one where there is more than one path through the grammar for the same utterance. This is not necessarily a bad thing.
Consider a company directory. There might be several people in the directory with the same name (say, "John Smith"). For proper recognition, each of these people must have its own place in the recognition grammar. Because there is more than one way to recognize "John Smith" in this grammar, we say that is "ambiguous".
Therefore, when a speaker says "John Smith", there will be multiple interpretations returned within the result for "John Smith". Since they will all have the same confidence level and utterance, they are in the same result.
Of course, in order to take advantage of multiple interpretations, there must be a way to disambiguate them. This can be done using slots. For instance, each user in the directory will typically have a unique user id. This user id can be returned in a slot. The slot can be called "userid". Additional information for a user can be returned in other slots. For instance there could be a slot for the user's extension number. There may be another one to return the user's E-mail address.
This information could be used to, say, generate a disambiguation prompt so that the caller can choose which user they really want to call.
These steps are also designed to iterate through each result in the result collection and through each interpretation in each result. This is enabled by the fact that the Generic Recognition Step returns the number of results in the result collection. The Generic Recognition Result Info step in turn returns the number of interpretations within a selected result.
This information can be used along with the Go To step and the Conditional step to walk through all the interpretations in all the results.
Note | There is no way to "introspect" the set of slots returned in an interpretation. The script must be designed along with the grammar so that it knows what slots are going to be filled in by the grammar for each interpretation. |