This documentation corresponds to an older version of the product, is no longer updated, and may contain outdated information.
Please access the latest versions from https://cisco-tailf.gitbook.io/nso-docs and update your bookmarks. OK
This section of documentation discusses all of the implementation details of services in NSO. The reader should be already familiar with all the concepts described in the introductory chapters and Implementing Services.
For an introduction to services, see Developing a Simple Service instead.
Each service type in NSO extends a part of the data model
(a list or a container) with the ncs:servicepoint
statement and the ncs:service-data grouping.
This is what defines an NSO service.
The service point instructs NSO to involve the service
machinery (Service Manager) for management of that part of the
data tree and the ncs:service-data grouping contains
definitions common to all services in NSO.
Defined in tailf-ncs-services.yang,
ncs:service-data includes parts that are required for
proper operation of FASTMAP and the Service Manager.
Every service must therefore use this grouping as part of its data
model.
In addition, ncs:service-data provides a common
service interface to the users, consisting of:
- check-sync, deep-check-sync actions
-
Check if the configuration created by the service is (still) there. That is, a re-deploy of this service would produce no changes.
The deep variant also retrieves the latest configuration from all the affected devices, making it relatively expensive.
- re-deploy, reactive-re-deploy actions
-
Re-run the service mapping logic and deploy any changes from the current configuration. Non-reactive variant supports commit parameters, such as dry-run.
Reactive variant performs an asynchronous re-deploy as the user of the original commit and uses the commit parameters from the latest commit of this service. It is often used with nano services, such as restarting a failed nano service.
- un-deploy action
-
Remove the configuration produced by the service instance but keep the instance data, allowing a re-deploy later. This action effectively deactivates the service, while keeping it in the system.
- get-modifications action
-
Show the changes in the configuration that this service instance produced. Behaves as if this was the only service that made the changes.
- touch action
-
Available in the configure mode, marks the service as being changed and allows re-deploying multiple services in the same transaction.
-
directly-modified,modifiedcontainers -
List devices and services the configuration produced by this service affects directly or indirectly (through other services).
-
used-by-customer-serviceleaf-list -
List of customer services (defined under
/services/customer-service) that this service is part of. Customer service is an optional concept that allows you to group multiple NSO services as belonging to the same customer. -
commit-queuecontainer -
Contains commit queue items related to this service. See the section called “Commit Queue” in User Guide for details.
-
created,last-modified,last-runleafs -
Date and time of the main service events.
-
logcontainer -
Contains log entries for important service events, such as those related to the commit queue or generated by user code. Defined in
tailf-ncs-log.yang. -
plan-locationleaf -
Location of the plan data if service plan is used. See Nano Services for Staged Provisioning for more on service plans and using alternative plan locations.
While not part of ncs:service-data as such, you may
consider the service-commit-queue-event notification
part of the core service interface. The notification provides
information about the state of the service when service uses
the commit queue.
As an example, an event-driven application uses this notification
to find out when a service instance has been deployed to the devices.
See the showcase_rc.py script in
examples.ncs/development-guide/concurrency-model/perf-stack/
for sample Python code, leveraging the notification.
See tailf-ncs-services.yang for the full
definition of the notification.
NSO Service Manager is responsible for providing the functionality of the common service interface, requiring no additional user code. This interface is the same for classic and nano services, whereas nano services further extend the model.
NSO calls into Service Manager when accessing actions and operational data under the common service interface, or when the service instance configuration data (the data under the service point) changes. NSO being a transactional system, configuration data changes happen in a transaction.
When applied, a transaction goes through multiple stages, as shown by the progress trace (e.g. using commit | details in the CLI). The detailed output breaks up the transaction into four distinct phases:
-
validation
-
write-start
-
prepare
-
commit
These phases deal with how the network-wide transactions work: validation phase prepares and validates the new configuration (including NSO copy of device configurations), then the CDB processes the changes and prepares them for local storage in the write-start phase. The prepare stage sends out the changes to network through the Device Manager and the HA system. The changes are staged (e.g. in candidate data store) and validated if device supports it, otherwise the changes are activated immediately. If all systems took the new configuration successfully, enter the commit phase, marking the new NSO configuration as active and activating or committing the staged configuration on remote devices. Otherwise, enter the abort phase, discarding changes and ask NEDs to revert activated changes on devices that do not support transactions (e.g. without candidate data store).
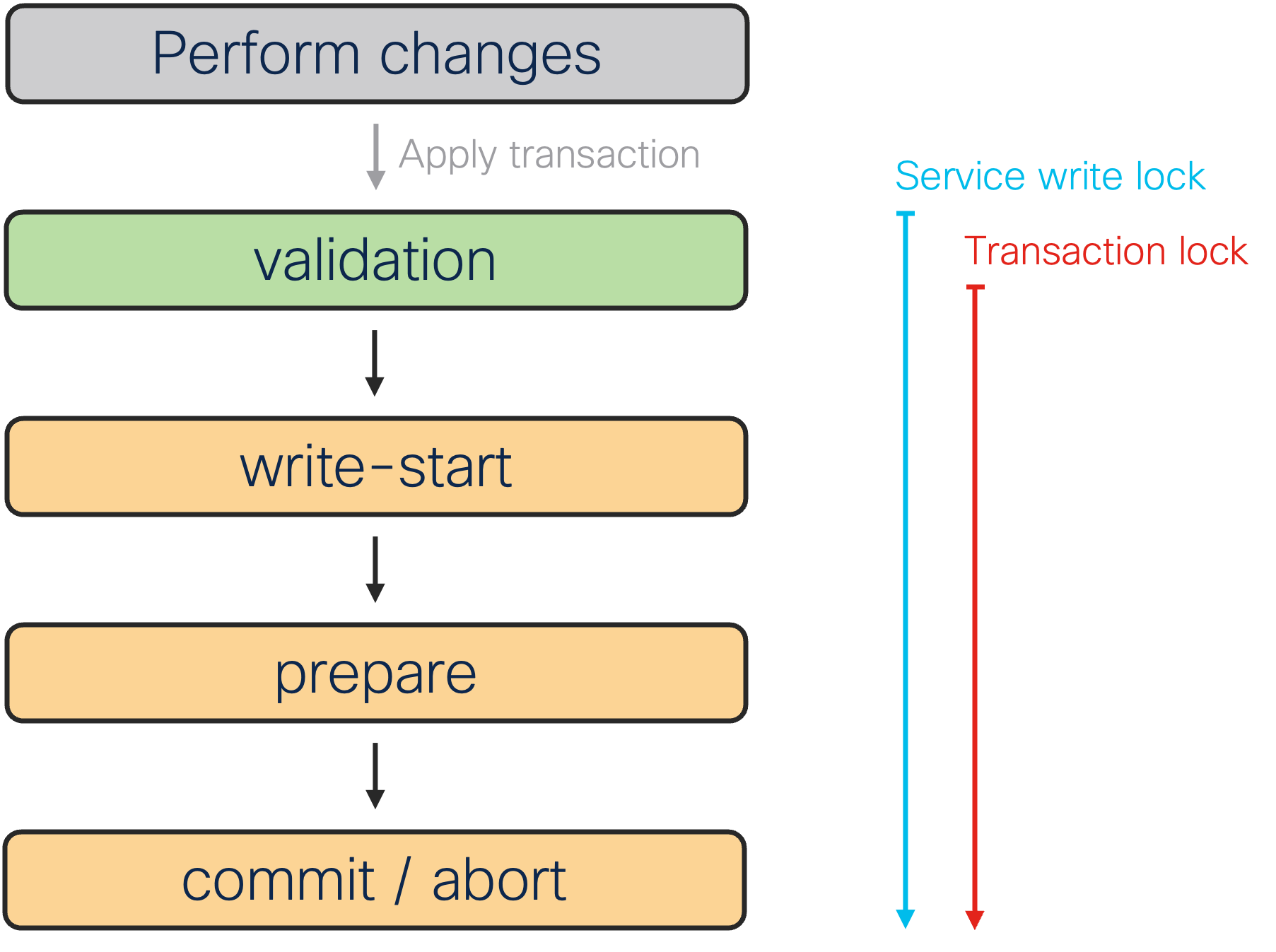
There are also two types of locks involved with the transaction that are of interest to service developer; the service write lock and the transaction lock. The latter is a global lock, required to serialize transactions, while the former is a per-service-type lock for serializing services that cannot be run in parallel. See Scaling and Performance Optimization for more details and their impact on performance.
The first phase, historically called validation, does more than just validate data and is the phase a service deals with the most. The other three support the NSO service framework but a service developer rarely interacts with directly.
We can further break down the first phase into the following stages:
-
rollback creation
-
pre-transform validation
-
transforms
-
full data validation
-
conflict check and transaction lock
When transaction starts applying, NSO captures the initial intent and creates a rollback file, which allows one to reverse or roll back the intent. For example, the rollback file might contain the information that you changed a service instance parameter but it would not contain the service-produced device changes.
Then the first, partial validation takes place. It ensures the service input parameters are valid according to the service YANG model, so the service code can safely use provided parameter values.
Next, NSO runs transaction hooks and performs the necessary transforms, which alter the data before it is saved, for example encrypting passwords. This is also where Service Manager invokes FASTMAP and service mapping callbacks, recording the resulting changes. NSO takes service write locks in this stage, too.
After transforms, there are no more changes to the configuration data and the full validation starts, including YANG model constraints over the complete configuration, custom validation through validation points, and configuration policies (the section called “Policies” in User Guide).
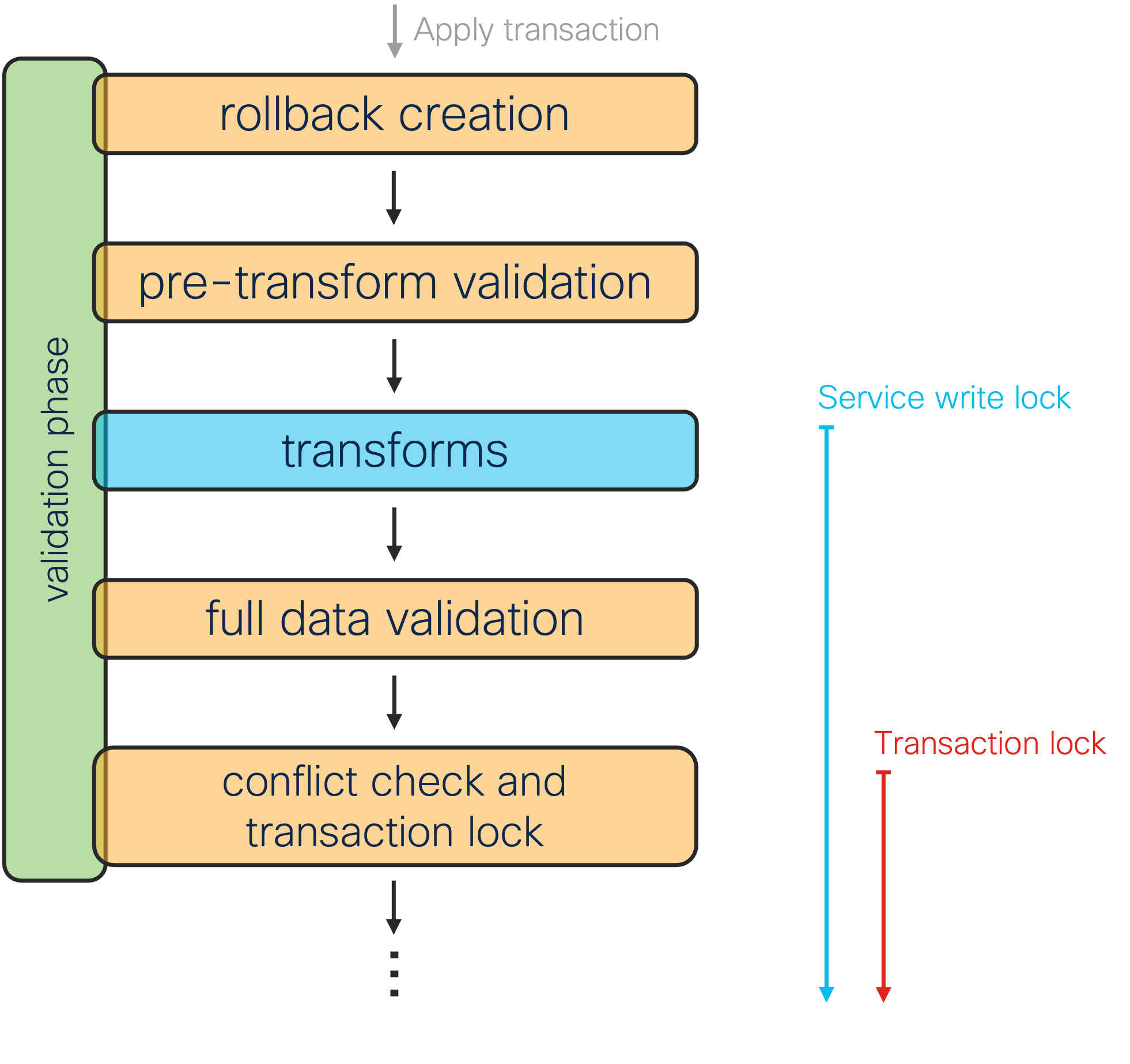
Throughout the phase, transaction engine makes checkpoints, so it can restart the transaction faster in case of concurrency conflicts. The check for conflicts happens at the end of this first phase, when NSO also takes the global transaction lock. Concurrency is further discussed in NSO Concurrency Model.
The main callback associated with a service point is the create callback, designed to produce the required (new) configuration, while FASTMAP takes care of the other operations, such as update and delete.
NSO implements two additional, optional callbacks for scenarios where create is insufficient. These are pre- and post-modification callbacks that NSO invokes before (pre) or after (post) create. These callbacks work outside of the scope tracked by FASTMAP. That is, changes done in pre- and post-modification do not automatically get removed during update or delete of the service instance.
For example, you can use the pre-modification callback to check the service prerequisites (pre-check) or make changes that you want persisted even after the service is removed, such as enabling some global device feature. The latter may be required when NSO is not the only system managing the device and removing the feature configuration would break non-NSO managed services.
Similarly, you might use post-modification to reset the configuration to some default after the service is removed. Say the service configures an interface on a router for customer VPN. However, when the service is deprovisioned (removed), you don't want to simply erase the interface configuration. Instead, you want to put it in shutdown and configure it for a special, unused VLAN. The post-modification callback allows you to achieve this goal.
The main difference from create callback is
that pre- and
post-modification are called on update and
delete, as well as service create. Since the service data node
may no longer exist in case of delete, the API for these callbacks
does not supply the service object.
Instead, the callback receives the operation and key path to the
service instance. See the following API signatures for details.
@Service.pre_modification def cb_pre_modification(self, tctx, op, kp, root, proplist): ... @Service.create def cb_create(self, tctx, root, service, proplist): ... @Service.post_modification def cb_post_modification(self, tctx, op, kp, root, proplist): ...
The Python callbacks use the following function arguments:
- tctx
-
A TransCtxRef object containing transaction data, such as user session and transaction handle information.
- op
-
Integer representing operation: create (
ncs.dp.NCS_SERVICE_CREATE), update (ncs.dp.NCS_SERVICE_UPDATE), or delete (ncs.dp.NCS_SERVICE_DELETE) of the service instance. - kp
-
A HKeypathRef object with a key path of the affected service instance, such as
/svc:my-service{instance1}. - root
-
A Maagic node for the root of the data model.
- service
-
A Maagic node for the service instance.
- proplist
-
Opaque service properties, see the section called “Persistent Opaque Data”.
@ServiceCallback(servicePoint = "...", callType = ServiceCBType.PRE_MODIFICATION) public Properties preModification(ServiceContext context, ServiceOperationType operation, ConfPath path, Properties opaque) throws DpCallbackException; @ServiceCallback(servicePoint="...", callType=ServiceCBType.CREATE) public Properties create(ServiceContext context, NavuNode service, NavuNode ncsRoot, Properties opaque) throws DpCallbackException; @ServiceCallback(servicePoint = "...", callType = ServiceCBType.POST_MODIFICATION) public Properties postModification(ServiceContext context, ServiceOperationType operation, ConfPath path, Properties opaque) throws DpCallbackException;
The Java callbacks use the following function arguments:
- context
-
A ServiceContext object for accessing root and service instance NavuNode in the current transaction.
- operation
-
ServiceOperationType enum representing operation:
CREATE,UPDATE,DELETEof the service instance. - path
-
A ConfPath object with a key path of the affected service instance, such as
/svc:my-service{instance1}. - ncsRoot
-
A NavuNode for the root of the
ncsdata model. - service
-
A NavuNode for the service instance.
- opaque
-
Opaque service properties, see the section called “Persistent Opaque Data”.
See examples.ncs/development-guide/services/post-modification-py
and examples.ncs/development-guide/services/post-modification-java
examples for a sample implementation of the
post-modification callback.
Additionally, you may implement these callbacks with templates. Refer to the section called “Service callpoints and templates” for details.
FASTMAP greatly simplifies service code, so it usually only needs to deal with the initial mapping. NSO achieves this by first discarding all the configuration performed during the create callback of the previous run. In other words, the service create code always starts anew, with a blank slate.
If you need to keep some private service data across runs of the create callback, or pass data between callbacks, such as pre- and post-modification, you can use opaque properties.
The opaque object is available in the service callbacks as an
argument, typically named proplist (Python) or
opaque (Java). It contains a set of named
properties with their corresponding values.
If you wish to use the opaque properties, it is crucial that your code returns the properties object from the create call, otherwise, the service machinery will not save the new version.
Compared to pre- and post-modification callbacks, which also persist data outside of FASTMAP, NSO deletes the opaque data when the service instance is deleted, unlike with the pre- and post-modification data.
proplist in Python
@Service.create
def cb_create(self, tctx, root, service, proplist):
intf = None
# proplist is of type list[tuple[str, str]]
for pname, pvalue in proplist:
if pname == 'INTERFACE':
intf = pvalue
if intf is None:
intf = '...'
proplist.append('INTERFACE', intf)
return proplistopaque in Java
public Properties create(ServiceContext context,
NavuNode service,
NavuNode ncsRoot,
Properties opaque)
throws DpCallbackException {
// In Java API, opaque is null when service instance is first created.
if (opaque == null) {
opaque = new Properties();
}
String intf = opaque.getProperty("INTERFACE");
if (intf == null) {
intf = "...";
opaque.setProperty("INTERFACE", intf);
}
return opaque;
}
The examples.ncs/development-guide/services/post-modification-py
and examples.ncs/development-guide/services/post-modification-java
examples showcase the use of opaque properties.
NSO by default enables concurrent scheduling and execution of services to maximize throughput. However, concurrent execution can be problematic for non-thread-safe services or services that are known to always conflict with themselves or other services, such as when they read and write the same shared data. See NSO Concurrency Model for details.
To prevent NSO from scheduling a service instance together
with an instance of another service, declare a static conflict in
the service model, using the ncs:conflicts-with
extension.
The following example shows a service with two declared static
conflicts, one with itself and one with another service, named
other-service.
list example-service {
key name;
leaf name {
type string;
}
uses ncs:service-data;
ncs:servicepoint example-service {
ncs:conflicts-with example-service;
ncs:conflicts-with other-service;
}
}This means each service instance will wait for other service instances that have started sooner than this one (and are of example-service or other-service type) to finish before proceeding.
FASTMAP knows that a particular piece of configuration belongs to a service instance, allowing NSO to revert the change as needed. But what happens when several service instances share a resource that may or may not exist before the first service instance is created? If the service implementation naively checks for existence and creates the resource when it is missing, then the resource will be tracked with the first service instance only. If, later on, this first instance is removed, then the shared resource is also removed, affecting all other instances.
A well-known solution to this kind of problem is reference counting.
NSO uses reference counting by default with the XML templates
and Python Maagic API, while in Java Maapi and Navu APIs, the
sharedCreate(), sharedSet(),
and sharedSetValues() functions need to
be used.
When enabled, the reference counter allows FASTMAP algorithm to
keep track of the usage and only delete data when the last service
instance referring to this data is removed.
Furthermore, containers and list items created using the
sharedCreate() and
sharedSetValues() functions also get an
additional attribute called backpointer.
(But this functionality is currently not available for individual
leafs.)
Backpointer points back to the service instance that created the
entity in the first place. This makes it possible to look at part
of the configuration, say under /devices tree, and answer
the question: which parts of the device configuration were created
by which service?
To see reference counting in action, start the
examples.ncs/implement-a-service/iface-v3
example with make demo and configure a service
instance.
admin@ncs(config)#iface instance1 device c1 interface 0/1 ip-address 10.1.2.3 cidr-netmask 28admin@ncs(config)#commit
Then configure another service instance with the same parameters and use the display service-meta-data pipe to show the reference counts and backpointers:
admin@ncs(config)#iface instance2 device c1 interface 0/1 ip-address 10.1.2.3 cidr-netmask 28admin@ncs(config)#commit dry-runcli { local-node { data +iface instance2 { + device c1; + interface 0/1; + ip-address 10.1.2.3; + cidr-netmask 28; +} } } admin@ncs(config)#commit and-quitadmin@ncs#show running-config devices device c1 config interface\ GigabitEthernet 0/1 | display service-meta-datadevices device c1 config ! Refcount: 2 ! Backpointer: [ /iface:iface[iface:name='instance1'] /iface:iface[iface:name='instance2'] ] interface GigabitEthernet0/1 ! Refcount: 2 ip address 10.1.2.3 255.255.255.240 ! Refcount: 2 ! Backpointer: [ /iface:iface[iface:name='instance1'] /iface:iface[iface:name='instance2'] ] ip dhcp snooping trust exit ! !
Notice how commit dry-run produces no new
device configuration but the system still tracks the changes.
If you wish, remove the first instance and verify the
GigabitEthernet 0/1 configuration is still
there, but is gone when you also remove the second one.
But what happens if the two services produce different configuration
for the same node? Say, one sets the IP address to
10.1.2.3 and the other to
10.1.2.4.
Conceptually, these two services are incompatible and instantiating
both at the same time produces broken configuration (instantiating
the second service instance breaks the configuration for the first).
What is worse is that the current configuration depends on the order
the services were deployed or re-deployed.
For example, re-deploying the first service will change the
configuration from 10.1.2.4 back to
10.1.2.3 and vice versa.
Such inconsistencies break the declarative configuration model
and really should be avoided.
In practice, however, NSO does not prevent services from producing such configuration. But note that we strongly recommend against it and that there are associated limitations, such as service un-deploy not reverting configuration to that produced by the other instance (but when all services are removed, the original configuration is still restored). The commit | debug service pipe command warns about any such conflict that it finds but may miss conflicts on individual leafs. The best practice is to use integration tests in the service development life cycle to ensure there are no conflicts, especially when multiple teams develop their own set of services that are to be deployed on the same NSO instance.
Much like a service in NSO can provisioning device configurations, it can also provision other, non-device data, as well as other services. We call the approach of services provisioning other services service stacking and the services that are involved — stacked.
Service stacking concepts usually come into play for bigger, more complex services. There are a number of reasons why you might prefer stacked services to a single monolithic one:
-
Smaller, more manageable services with simpler logic
-
Separation of concerns and responsibility
-
Clearer ownership across teams for (parts of) overall service
-
Smaller services reusable as components across the solution
-
Avoiding overlapping configuration between service instances causing conflicts, such as using one service instance per device (see examples in the section called “Designing for Maximal Transaction Throughput”)
Stacked services are also the basis for LSA, which takes this concept even further. See Layered Service Architecture for details.
The standard naming convention with stacked services distinguishes between a Resource-Facing Service (RFS), that directly configures one or more devices, and a Customer-Facing Service (CFS), that is the top-level service, configuring only other services, not devices. There can be more than two layers of services in the stack, too.
While NSO does not prevent a single service from configuring devices as well as services, in the majority of cases this results in a less clean design and is best avoided.
Overall, creating stacked services is very similar to the non-stacked approach. First, you can design the RFS services as usual. Actually, you might take existing services and reuse those. These then become your lower-level services, since they are lower in the stack.
Then you create a higher-level service, say a CFS, that configures another service, or a few, instead of a device. You can even use a template-only service to do that, such as:
<config-template xmlns="http://tail-f.com/ns/config/1.0" servicepoint="top-level-service"> <iface xmlns="http://com/example/iface"> <name>instance1</name> <device>c1</device> <interface>0/1</interface> <ip-address>10.1.2.3</ip-address> <cidr-netmask>28</cidr-netmask> </iface> </config>
The preceding example references an existing
iface service, such as the one in the
examples.ncs/implement-a-service/iface-v3
example. The output shows hard-coded values but you can change
those as you would for any other service.
In practice, you might find it beneficial to modularize your data model and potentially reuse parts in both, the lower- and higher-level service. This avoids duplication while still allowing you to directly expose some of the lower-level service functionality through the higher-level model.
The most important principle to keep in mind is that the data created by any service is owned by that service, regardless of how the mapping is done (through code or templates). If the user deletes a service instance, FASTMAP will automatically delete whatever the service created, including any other services. Likewise, if the operator directly manipulates service data that is created by another service, the higher-level service becomes out of sync. The check-sync service action checks this for services as well as devices.
In stacked service design, the lower-level service data is under the control of the higher-level service and must not be directly manipulated. Only the higher-level service may manipulate that data. However, two higher-level services may manipulate the same structures, since NSO performs reference counting (see the section called “Reference Counting Overlapping Configuration”).
This section lists some specific advice for implementing services, as well as any known limitations you might run into.
You may also obtain some useful information by using the debug service commit pipe command, such as commit dry-run | debug service. The command display the net effect of the service create code, as well as issue warnings about potentially problematic usage of overlapping shared data.
-
Service callbacks must be deterministic
NSO invokes service callbacks in a number of situations, such as for dry-run, check sync, and actual provisioning. If a service does not create the same configuration from the same inputs, NSO sees it as being out of sync, resulting in a lot of configuration churn and making it incompatible with many NSO features.
If you need to introduce some randomness or rely on some other nondeterministic source of data, make sure to cache the values across callback invocations, such as by using opaque properties (the section called “Persistent Opaque Data”) or persistent operational data (the section called “Operational Data”) populated in a pre-modification callback.
-
Never overwrite service inputs
Service input parameters capture client intent and a service should never change its own configuration. Such behavior not only muddles the intent but is also temporary when done in the create callback, as the changes are reverted on the next invocation.
If you need to keep some additional data that cannot be easily computed each time, consider using opaque properties (the section called “Persistent Opaque Data”) or persistent operational data (the section called “Operational Data”) populated in a pre-modification callback.
-
No service ordering in a transaction
NSO is a transactional system and as such does not have the concept of order inside a single transaction. That means NSO does not guarantee any specific order in which the service mapping code executes if the same transaction touches multiple service instances. Likewise, your code should not make any assumptions about running before or after other service code.
-
Return value of create callback
The create callback is not the exclusive user of the opaque object; the object can be chained in several different callbacks, such as pre- and post-modification. Therefore, returning
None/nullfrom create callback is not a good practice. Instead, always return the opaque object even if the create callback does not use it. -
Avoid delete in service create
Unlike creation, deleting configuration does not support reference counting, as there is no data left to reference count. This means the deleted elements are tied to the service instance that deleted them.
Additionally, FASTMAP must store the entire deleted tree and restore it on every service change or re-deploy, only to be deleted again. Depending on the amount of deleted data, this is potentially an expensive operation.
So, a general rule of thumb is to never use delete in service create code. If an explicit delete is used, debug service may display the following warning:
*** WARNING ***: delete in service create code is unsafe if data is shared by other servicesHowever, service may also delete data implicitly, through
whenandchoicestatements in the YANG data model. If awhenstatement evaluates to false, the configuration tree below that node is deleted. Likewise, if acaseis set in achoicestatement, the previously setcaseis deleted. This has the same limitations as an explicit delete.To avoid these issues, create a separate service, which only handles deletion, and use it in the main service through the stacked service design (see the section called “Stacked Services”). This approach allows you to reference count the deletion operation and contain the effect of restoring deleted data through a small, rarely-changing helper service. See
examples.ncs/development-guide/services/shared-deletefor an example.Alternatively, you might consider pre- and post-modification callbacks for some specific cases.
-
Prefer
shared*()functionsNon-shared create and set operations in the Java and Python low-level API do not add reference counts or backpointer information to changed elements. In case there is overlap with another service, unwanted removal can occur. See the section called “Reference Counting Overlapping Configuration” for details.
In general, you should prefer
sharedCreate(),sharedSet(), andsharedSetValues(). If non-shared variants are used in a shared context, service debug displays a warning, such as:*** WARNING ***: set in service create code is unsafe if data is shared by other servicesLikewise, do not use MAAPI
load_configvariants from service code. Use thesharedSetValues()function to load XML data from a file or a string. -
Reordering ordered-by-user lists
If service code rearranges an ordered-by-user list with items that were created by another service, that other service becomes out of sync. In some cases you might be able to avoid out-of-sync scenario by leveraging special XML template syntax (see the section called “Operations on ordered lists and leaf-lists”) or using service stacking with a helper service.
In general, however, you should reconsider your design and try to avoid such scenarios.
-
Automatic upgrade of keys for existing services is unsupported
Service backpointers, described in the section called “Reference Counting Overlapping Configuration”, rely on the keys that the service model defines to identify individual service instances. If you update the model by adding, removing, or changing the type of leafs used in the service list key, while there are deployed service instances, the backpointers will not be automatically updated. Therefore, it is best to not change the service list key.
A workaround, if service key absolutely must change, is to first perform a no-networking undeploy of the affected service instances, then upgrade the model, and finally no-networking re-deploy the previously un-deployed services.
-
Avoid conflicting intents
Consider that a service is executed as part of a transaction. If, in the same transaction, the service gets conflicting intents, for example, it gets modified and deleted, the transaction is aborted. You must decide which intent has higher priority and design your services to avoid such situations.
A very common situation, when NSO is deployed in an existing network, is that the network already has services implemented. These services may have been deployed manually or through an older provisioning system. To take full advantage of the new system, you should consider importing the existing services into NSO. The goal is to use NSO to manage existing service instances, along with adding new ones in the future.
The process of identifying services and importing them into NSO is called Service Discovery and can be broken down into the following high-level parts:
-
Implementing the service to match existing device configuration.
-
Enumerating service instances and their parameters.
-
Amend the service meta data references with reconciliation.
Ultimately, the problem that service discovery addresses is one of referencing or linking configuration to services. Since the network already contains target configuration, a new service instance in NSO produces no changes in the network. This means the new service in NSO by default does not own the network configuration. One side effect is that removing a service will not remove the corresponding device configuration, which is likely to interfere with service modification as well.
Some of the steps in the process can be automated, while others are mostly manual. The amount of work differs a lot depending on how structured and consistent the original deployment is.
A prerequisite (or possibly the product in an iterative approach) is an NSO service that supports all the different variants of the configuration for the service that are used in the network. This usually means there will be a few additional parameters in the service model that allow selecting the variant of device configuration produced, as well as some covering other non-standard configuration (if such configuration is present).
In the simplest case, there is only one variant and that is the
one that the service needs to produce. Let's take the
examples.ncs/implement-a-service/iface-v2-py
example and consider what happens when a device already has
existing interface configuration.
admin@ncs# show running-config devices device c1 config\
interface GigabitEthernet 0/1
devices device c1
config
interface GigabitEthernet0/1
ip address 10.1.2.3 255.255.255.240
exit
!
!Configuring a new service instance does not produce any new device configuration (notice that device c1 has no changes).
admin@ncs(config)# commit dry-run
cli {
local-node {
data +iface instance1 {
+ device c1;
+ interface 0/1;
+ ip-address 10.1.2.3;
+ cidr-netmask 28;
+}
}
}However, when committed, NSO records the changes, just like in the case of overlapping configuration (the section called “Reference Counting Overlapping Configuration”). The main difference is that there is only a single backpointer, to a newly configured service, but the refcount is 2. The other item, that contributes to the refcount, is the original device configuration. Which is why the configuration is not deleted when the service instance is.
admin@ncs# show running-config devices device c1 config interface\
GigabitEthernet 0/1 | display service-meta-data
devices device c1
config
! Refcount: 2
! Backpointer: [ /iface:iface[iface:name='instance1'] ]
interface GigabitEthernet0/1
! Refcount: 2
! Originalvalue: 10.1.2.3
ip address 10.1.2.3 255.255.255.240
exit
!
!A prerequisite for service discovery to work is that it is possible to construct a list of the already existing services. Such a list may exist in an inventory system, an external database, or perhaps just an Excel spreadsheet.
You can import the list of services in a number of ways. If you are reading it in from a spreadsheet, a Python script using NSO API directly (Basic Automation with Python) and a module to read Excel files is likely a good choice.
import ncs
from openpyxl import load_workbook
def main()
wb = load_workbook('services.xslx')
sheet = wb[wb.sheetnames[0]]
with ncs.maapi.single_write_trans('admin', 'python') as t:
root = ncs.maagic.get_root(t)
for sr in sheet.rows:
# Suppose columns in spreadsheet are:
# instance (A), device (B), interface (C), IP (D), mask (E)
name = sr[0].value
service = root.iface.create(name)
service.device = sr[1].value
service.interface = sr[2].value
service.ip_address = sr[3].value
service.cidr_netmask = sr[4].value
t.apply()
main()Or you might generate an XML data file to import using the ncs_load command; use display xml filter to help you create a template:
admin@ncs# show running-config iface | display xml
<config xmlns="http://tail-f.com/ns/config/1.0">
<iface xmlns="http://com/example/iface">
<name>instance1</name>
<device>c1</device>
<interface>0/1</interface>
<ip-address>10.1.2.3</ip-address>
<cidr-netmask>28</cidr-netmask>
</iface>
</config>Regardless of the way you implement the data import, you can run into two kinds of problems.
On one hand, the service list data may be incomplete. Suppose that the earliest service instances deployed did not take the network mask as a parameter. Moreover, for some specific reasons, a number of interfaces had to deviate from the default of 28 and that information was never populated back in the inventory for old services after the netmask parameter was added.
Now the only place where that information is still kept may be the actual device configuration. Fortunately, you can access it through NSO, which may allow you to extract the missing data automatically, for example:
devconfig = root.devices.device[service.device].config
intf = devconfig.interface.GigabitEthernet[service.interface]
netmask = intf.ip.address.primary.mask
cidr = IPv4Network(f'0.0.0.0/{netmask}').prefixlenOn the other hand, some parameters may be NSO specific, such as those controlling which variant of configuration to produce. Again, you might be able to use a script to find this information, or it could turn out that the configuration is too complex to make such a script feasible.
In general, this can be the most tricky part of the service discovery process, making it very hard to automate. It all comes down to how good the existing data is. Keep in mind that this exercise is typically also a cleanup exercise, and every network will be different.
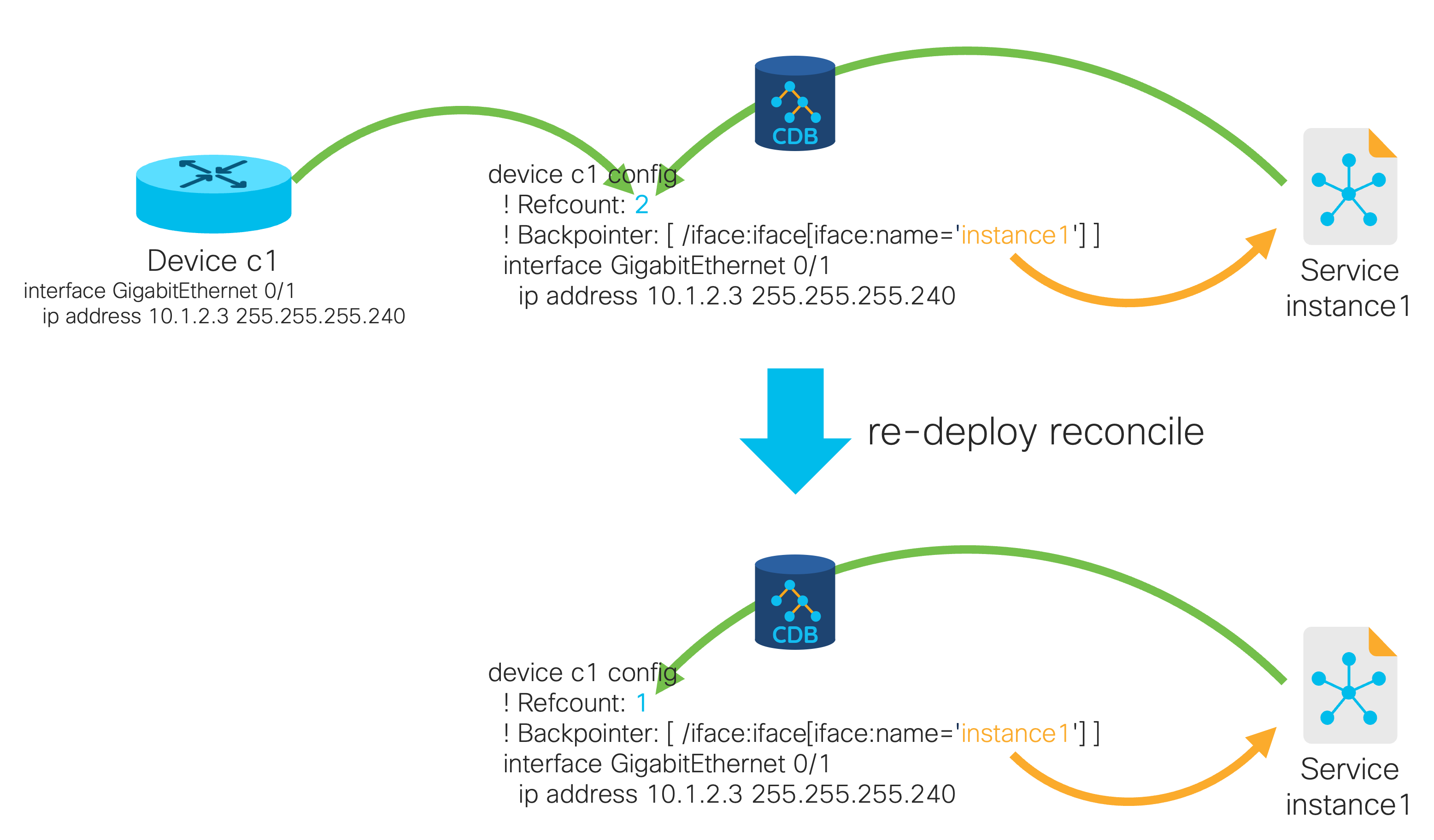
The last step is updating the meta data, telling NSO that a given service controls (owns) the device configuration that was already present when the NSO service was configured. This is called reconciliation and you achieve it using a special re-deploy reconcile action for the service.
Let's examine the effects of this action on the following data:
admin@ncs# show running-config devices device c1 config\
interface GigabitEthernet 0/1 | display service-meta-data
devices device c1
config
! Refcount: 2
! Backpointer: [ /iface:iface[iface:name='instance1'] ]
interface GigabitEthernet0/1
! Refcount: 2
! Originalvalue: 10.1.2.3
ip address 10.1.2.3 255.255.255.240
exit
!
!Having run the action, NSO has updated the refcount to remove the reference to the original device configuration:
admin@ncs#iface instance1 re-deploy reconcileadmin@ncs#show running-config devices device c1 config\ interface GigabitEthernet 0/1 | display service-meta-datadevices device c1 config ! Refcount: 1 ! Backpointer: [ /iface:iface[iface:name='instance1'] ] interface GigabitEthernet0/1 ! Refcount: 1 ip address 10.1.2.3 255.255.255.240 exit ! !
What is more, the reconcile algorithm works even if multiple service instances share configuration. What if you had two instances of the iface service, instead of one?
Before reconciliation the device configuration would show a refcount of three.
admin@ncs# show running-config devices device c1 config\
interface GigabitEthernet 0/1 | display service-meta-data
devices device c1
config
! Refcount: 3
! Backpointer: [ /iface:iface[iface:name='instance1'] /iface:iface[iface:name='instance2'] ]
interface GigabitEthernet0/1
! Refcount: 3
! Originalvalue: 10.1.2.3
ip address 10.1.2.3 255.255.255.240
exit
!
!Invoking re-deploy reconcile on either one or both of the instances makes the services sole owners of the configuration.
admin@ncs# show running-config devices device c1 config\
interface GigabitEthernet 0/1 | display service-meta-data
devices device c1
config
! Refcount: 2
! Backpointer: [ /iface:iface[iface:name='instance1'] /iface:iface[iface:name='instance2'] ]
interface GigabitEthernet0/1
! Refcount: 2
ip address 10.1.2.3 255.255.255.240
exit
!
!This means the device configuration is removed only when you remove both service instances.
admin@ncs(config)#no iface instance1admin@ncs(config)#commit dry-run outformat nativenative { } admin@ncs(config)#no iface instance2admin@ncs(config)#commit dry-run outformat nativenative { device { name c1 data no interface GigabitEthernet0/1 } }
The reconcile operation only removes the references to the original configuration (without the service backpointer), so you can execute it as many times as you wish. Just note that it is part of a service re-deploy, with all the implications that brings, such as potentially deploying new configuration to devices when you change the service template.
As an alternative to the re-deploy reconcile, you can initially add the service configuration with a commit reconcile variant, performing reconciliation right away.
It is hard to design a service in one go when you wish to cover existing configurations that are exceedingly complex or have a lot of variance. In such cases, many prefer an iterative approach, where you tackle the problem piece-by-piece.
Suppose there are two variants of the service configured in the network; iface-v2-py and the newer iface-v3, which produces a slightly different configuration. This is a typical scenario when a different (non-NSO) automation system is used and the service gradually evolves over time. Or when a Method of Procedure (MOP) is updated if manual provisioning is used.
We will tackle this scenario to show how you might perform service discovery in an iterative fashion. We shall start with the iface-v2-py as the first iteration of the iface service, which represents what configuration the service should produce to the best of our current knowledge.
There are configurations for two service instances in the network already: for interfaces 0/1 and 0/2 on the c1 device. So, configure the two corresponding iface instances.
admin@ncs(config)#commit dry-runcli { local-node { data +iface instance1 { + device c1; + interface 0/1; + ip-address 10.1.2.3; + cidr-netmask 28; +} +iface instance2 { + device c1; + interface 0/2; + ip-address 10.2.2.3; + cidr-netmask 28; +} } } admin@ncs(config)#commit
You can also use the commit no-deploy variant to add service parameters when normal commit would produce device changes, which you do not want.
Then use the re-deploy reconcile { discard-non-service-config } dry-run command to observe the difference between the service-produced configuration and the one present in the network.
admin@ncs# iface instance1 re-deploy reconcile\
{ discard-non-service-config } dry-run
cli {
}For instance1 the config is the same, so you can safely reconcile it already.
admin@ncs# iface instance1 re-deploy reconcileBut interface 0/2 (instance2), which you suspect was initially provisioned with the newer version of the service, produces the following:
admin@ncs# iface instance2 re-deploy reconcile\
{ discard-non-service-config } dry-run
cli {
local-node {
data devices {
device c1 {
config {
interface {
GigabitEthernet 0/2 {
ip {
dhcp {
snooping {
- trust;
}
}
}
}
}
}
}
}
}
}The output tells you that the service is missing the ip dhcp snooping trust part of the interface configuration. Since the service does not generate this part of the configuration yet, running re-deploy reconcile { discard-non-service-config } (without dry-run) would remove the DHCP trust setting. This is not what we want.
One option, and this is the default reconcile mode, would be to use keep-non-service-config instead of discard-non-service-config. But that would result in the service taking ownership of only part of the interface configuration (the IP address).
Instead, the right approach is to add the missing part to the service template. There is, however, a little problem. Adding the DHCP snooping trust configuration unconditionally to the template can interfere with the other service instance, instance1.
In some cases, upgrading the old configuration to the new variant is viable, but in most situations you likely want to avoid all device configuration changes. For the latter case, you need to add another parameter to the service model that selects the configuration variant. You must update the template too, producing the second iteration of the service.
iface instance2 device c1 interface 0/2 ip-address 10.2.2.3 cidr-netmask 28 variant v3 !
With the updated configuration, you can now safely reconcile the service2 service instance:
admin@ncs#iface instance2 re-deploy reconcile\ { discard-non-service-config } dry-runcli { } admin@ncs#iface instance2 re-deploy reconcile
Nevertheless, keep in mind that the discard-non-service-config
reconcile operation only considers parts of the device configuration
under nodes that are created with the service mapping.
Even if all data there is covered in the mapping, there could
still be other parts that belong to the service but reside in
an entirely different section of the device configuration
(say DNS configuration under ip name-server, which is
outside the interface GigabitEthernet part) or even
a different device.
That kind of configuration the discard-non-service-config option
cannot find on its own and you must add manually.
You can find the complete iface service as part of the
examples.ncs/development-guide/services/discovery
example.
Since there were only two service instances to reconcile, the process is now complete. In practice, you are likely to encounter multiple variants and many more service instances, requiring you to make additional iterations. But you can follow the iterative process shown here.
In some cases a service may need to rely on the actual device
configurations to compute the changeset. It is often a requirement to
pull the current device configurations from the network before
executing such service. Doing a full sync-from on a number of devices
is an expensive task, especially if it needs to be performed often.
The alternative way in this case is using partial-sync-from.
In cases where multitude of service instances touch a device that is not entirely
orchestrated using NSO, i.e. relying on the partial-sync-from feature described above,
and the device needs to be replaced then all services need to be re-deployed.
This can be expensive depending on the number of service instances.
Partial-sync-to enables replacement of devices in a more efficient fashion.
Partial-sync-from and partial-sync-to actions allow to specify
certain portions of the device's configuration to be pulled or pushed from or
to the network, respectively, rather than the full config. These are more efficient
operations on NETCONF devices and NEDs that support partial-show feature. NEDs that
do not support partial-show feature will fall back to pulling or pushing the whole configuration.
Even though partial-sync-from and partial-sync-to allows to pull
or push only a part of device's configuration, the actions are not allowed to break consistency
of configuration in CDB or on the device as defined by the YANG model. Hence, extra
consideration needs to be given to dependencies inside the device model.
If some configuration item A depends on configuration item B in the device's configuration,
pulling only A may fail due to unsatisfied dependency on B. In this case
both A and B need to be pulled, even if the service is only interested in the value of A.
It is important to note that partial-sync-from and partial-sync-to
clear the transaction ID of the device in NSO
unless the whole configuration has been selected
(e.g. /ncs:devices/ncs:device[ncs:name='ex0']/ncs:config).
This ensures NSO does not miss any changes to other parts of
the device configuration but it does make the device out of sync.
Pulling the configuration from the network needs to be initiated outside
the service code. At the same time the list of configuration subtrees
required by a certain service should be maintained by the service
developer. Hence it is a good practice for such service to implement a
wrapper action that invokes the generic /devices/partial-sync-from action
with the correct list of paths. The user or application that manages the
service would only need to invoke the wrapper action without needing to
know which parts of configuration the service is interested in.
The snippet in
Example 17, “Example of running partial-sync-from action via Java API”
gives an example of running partial-sync-from action via Java, using
"router" device from
examples.ncs/getting-started/developing-with-ncs/0-router-network.
ConfXMLParam[] params = new ConfXMLParam[] {
new ConfXMLParamValue("ncs", "path", new ConfList(new ConfValue[] {
new ConfBuf("/ncs:devices/ncs:device[ncs:name='ex0']/"
+ "ncs:config/r:sys/r:interfaces/r:interface[r:name='eth0']"),
new ConfBuf("/ncs:devices/ncs:device[ncs:name='ex1']/"
+ "ncs:config/r:sys/r:dns/r:server")
})),
new ConfXMLParamLeaf("ncs", "suppress-positive-result")};
ConfXMLParam[] result =
maapi.requestAction(params, "/ncs:devices/ncs:partial-sync-from");