Integrating Anomaly Detection with DevOps Processes
Automated and distributed systems can lead to challenges detecting anomalies — learn how to modernize your approach to anomaly detection.
Time to read: 8.5 minutes
As architectures have become more complex, the practice of detecting anomalies has followed. As we talked about in our article outlining how to improve system and application health, the complexity of microservices and nature of cloud-native applications has created anomalies or failures that are unpredictable and unique.
The human eye can miss anomalies in large and complex distributed systems, making it impractical to identify singular problems as they emerge. To keep stride with the pace of application releases, anomaly detection is best integrated into DevOps processes and paired with machine learning (ML).
This article will focus on anomaly detection in DevOps processes. But first, let’s explore anomaly detection in more detail.
The importance of anomaly detection
Anomaly detection is the process of observing data points and detecting any suspicious or rare events, i.e., outliers versus established patterns in data such as time series data. With the massive increase in data in recent years, manual tracking is simply impractical and inefficient.
Anomaly detection is not a new term. Data analysts used to perform this manually to uncover the root cause of a problem, with teams spending days detecting and correlating data from various sources.
These days, organizations capture huge amounts of data including business activity, various metrics, logs, security events, and so on. Meanwhile, acting fast has become increasingly important, as missing anomalies can damage your brand reputation, not to mention negatively impact revenues. Particularly in industries where customer data is of prime importance, not detecting suspicious events in time and ending up with a security breach can result in regulatory penalties and loss of customer trust.
Using machine learning, a system can learn data trends and patterns, which are then processed by the ML model and used as a baseline to detect anomalies. ML lets teams identify anomalies for individual metrics; you can then predict the possibility of an event causing cascading effects to proactively take the necessary steps to reduce the impact.
Anomaly detection vs. health rules
Before we dive into the reasons to implement anomaly detection, and provide guidance in adopting it, lets clear up the difference between anomaly detection and health rules. Both anomaly detection and health rules are used for alerting purposes, but have the following key differences:
- Health rules use manual threshold values known to cause issues
- Anomalies are significant deviations from the normal range of values
Thus, anomaly detection can cover a wider range of problems than rule-based detection techniques.
Anomaly detection is useful when one or more metrics are unknown or hard to identify, as it uses a pre-trained model.
In Full-Stack Observability, anomaly detection can be applied only to entity types within specific domains, namely, Application Performance Monitoring (APM), infrastructure, and Kubernetes. For example, in APM, business transactions, services, service endpoints, and service instances would be monitored for anomalies.
On the other hand, health rules can be applied to any entity type.
Why should I practice anomaly detection?
The following reasons to implement anomaly detection can improve any process or system.
Reason 1: Minimize MTTD (Mean Time to Detect)
Without anomaly detection, you can’t fully observe every part of a system, and are thus unable to understand what is causing issues that lead to shutdowns or performance degradation. Having fully automated observability with an anomaly detection feature, the system itself can uncover deep insights and correlate events to problems as they arise.
Anomaly detection is instrumental in minimizing MTTD by swiftly identifying deviations from normal behavior or patterns. The algorithms used continuously monitor data, quickly pinpointing unusual patterns or outliers that could indicate potential problems. Early detection drastically reduces the time between issue occurrence and identification, streamlining investigations and troubleshooting.
The automated nature of anomaly detection additionally allows it to handle large data volumes, detecting outliers in real time and minimizing manual monitoring efforts. With adaptable algorithms improving accuracy over time, the early identification of anomalies enables prompt intervention, which in turn prevents the escalation of problems, reduces overall downtime, and enhances system reliability.
Reason 2: Reduce human time spent searching for errors
Anomaly detection offers a pivotal advantage by enabling every team member to identify issues effectively, thereby decreasing reliance on specialized resources and frequently yielding superior results compared to human expertise.
This reduction in dependency on costly experts contributes significantly to curtailing operating expenses. Consequently, highly skilled talent can redirect their focus toward other critical facets of the business, boosting productivity in core and critical areas.
Reason 3: Assist causal analysis with machine learning
Anomaly detection plays a crucial role in facilitating causal analysis by quickly identifying irregularities or deviations from expected patterns within complex data sets. Analyzing these outliers can reveal underlying factors or events that contribute to the anomalies, aiding in the identification of a root cause.
Anomaly detection systems, when integrated with other analytical techniques or data sources, can assist in validating hypotheses about causal relationships between variables or events, offering insights into why certain anomalies occurred.
This process not only helps in understanding the immediate causes of anomalies but also deeper systemic issues, fostering more informed decision-making and proactive mitigation strategies.
Get started: Cisco’s AppDynamics provides a causal analysis feature.
Where should I implement anomaly detection in my DevOps process?
DevOps processes are important for the operational excellence of software, engineering productivity, system health, and security. The faster you detect issues and problems in these processes, the faster you can avoid potential issues such as unusual cost spikes, security events, delivery performance issues, etc.
Below, we cover some popular use cases for anomaly detection in DevOps.
Use Case 1: Use anomaly detection within application performance monitoring (APM) and service observability
Infrastructure monitoring includes VMs, disks, load balancers — anything that emits multidimensional time series metrics. Monitoring is required to identify their performance, saturation, and other errors like availability. This can also be enhanced by anomaly detection algorithms since, as discussed above, health rules might not work. Infrastructure metrics combined with APM data will provide detailed insights.
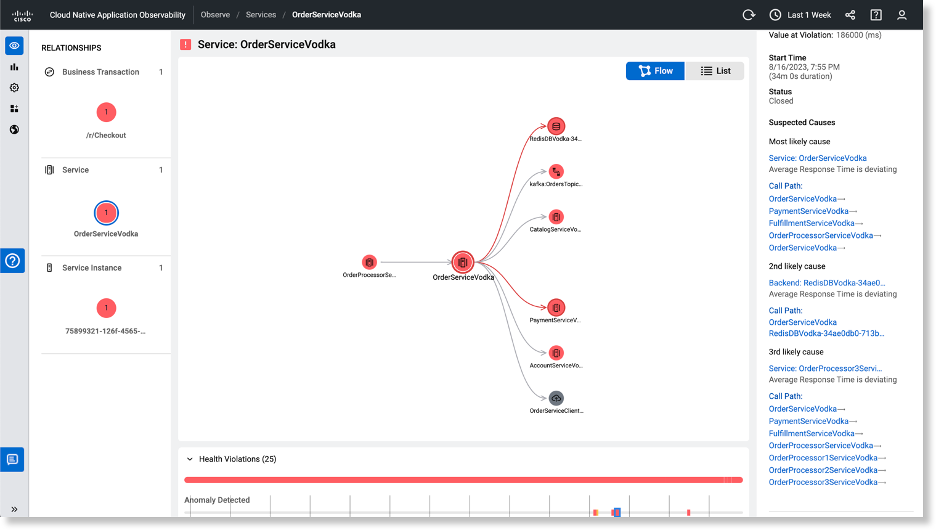
Figure 1: Entity health monitoring and causal analysis using anomaly detection (Source: Cisco AppDynamics)
Integrate anomaly detection within full-stack observability
Full stack observability of a mesh of distributed services creates a complex view of information. At the internet scale, a large amount of data is captured by the observability stack. APM captures signals like latency, traffic, apdex, and errors. Various metrics often don't have any predefined thresholds to monitor, so anomaly detection can help identify unusual events and then assist with causal analysis.
In distributed services, a changing trend that looks normal to human eyes could in fact be rare and point to a possible problem. In this case, a machine learning model trained on large amounts of historical data can better evaluate the shift and predict the future probability of an incident-causing event.
Use Case 2: Improve efficiency of cloud cost optimization and performance monitoring with anomaly detection
As the majority of companies use multiple cloud services to host their services, monitoring resources and costs is challenging for DevOps and FinOps practitioners. The following examples show how anomaly detection algorithms let DevOps teams become more efficient.
- Identify unusual spending patterns: Anomaly detection algorithms can analyze cloud cost metrics to identify unusual spending patterns. This helps DevOps teams quickly detect unexpected spikes in spend that may be due to misconfigurations, inefficient resource usage, or unexpected traffic.
- Create alerts for cost anomalies: Automated alerts can be set up to notify the DevOps team whenever there's a deviation from expected cost patterns. This enables timely investigation and intervention to prevent unnecessary expenses.
- Identify performance issues: Anomaly detection can be applied to various performance metrics like response times, memory utilization, CPU usage, and network traffic. DevOps teams can then identify abnormal behavior that may indicate performance bottlenecks or issues affecting user experience.
- Resolve issues proactively: DevOps teams can quickly identify and address performance issues by recognizing anomalies in real time, ensuring a smooth user experience. This helps in maintaining optimal service levels and prevents potential downtime.
- Detect resource underutilization or overutilization: Anomaly detection helps identify instances where resources are either underutilized or overutilized so that the DevOps team can right-size resources. This not only optimizes spend but also guarantees optimal software performance.
- Automate scaling decisions: Anomalies in resource usage patterns can trigger automated scaling decisions, allowing the infrastructure to dynamically adjust to changing workloads. This ensures efficient resource allocation and improves application scalability.
| Challenge | Solution |
|---|---|
| DevOps professionals frequently examine trends manually in cloud expenditures, a process that can be time-consuming. Unfortunately, this approach often leads to delayed responses to emerging issues, hindering the ability to proactively address growing concerns and effectively manage costs. | A viable solution to this challenge involves implementing anomaly detection-based alerts, which provide timely insights into notable spikes in costs; this in turn enables prompt and informed actions to keep expenses under control. |
Use case 3: Speed up root cause analysis
Root cause analysis is necessary in DevOps to identify and address the underlying causes of problems. It is crucial for continuous improvement and to prevent future issues from occurring, allowing organizations to quickly identify and resolve performance bottlenecks.
Pinpoint issues quickly
Anomaly detection can help DevOps teams pinpoint the root cause of issues more quickly. Whether it's a sudden increase in costs or a performance bottleneck, identifying anomalies narrows down the focus for troubleshooting and resolution.
Reduce mean time to resolution (MTTR)
By accelerating the identification of issues, anomaly detection contributes to reducing MTTR. This is critical for maintaining service levels and minimizing any impact on users.
Use case 4: Create a more adaptive infrastructure management
Anomaly detection enables a more adaptive and responsive approach to infrastructure management. DevOps teams can dynamically adjust resources based on real-time insights, optimizing both cost and performance in a continuously changing environment.
Use case 5: Secure systems by detecting unusual patterns
Any company can become a victim of security breaches, and data leaks or downtimes can not only destroy brand equity but also revenues. Identifying unusual patterns in traffic, hacking and penetration attempts, and ever-changing types of attacks are hard to observe without the use of machine learning techniques. Anomaly detection algorithms are key to identifying such issues in real time and immediately responding to them.
How to Use Cisco Full-Stack Observability for anomaly detection
Full-stack observability tools like Cisco AppDynamics monitor various cloud entities such as EC2 metrics, load balancer metrics, and Kubernetes workloads. In these scenarios, it applies anomaly detection algorithms to proactively identify issues. Cisco has implemented machine learning in their products for this purpose, including Cisco AppDynamics, Cisco ThousandEyes, and Cisco Cloud Application Observability.
These products leverage multiple techniques to disregard any temporary spike or periods of no data, normalizes metrics data, and apply baselines to detect daily and weekly data seasonality. They also gives a higher weighting to certain metrics to improve accuracy. For example, in APM, a spike seen in metrics like errors/sec is more critical than one in calls/sec, as a spike in calls/sec may not be a real problem.
DevOps teams can improve maturity with anomaly detection
Based on our above discussion on anomaly detection and its application in DevOps processes, it’s clear how your DevOps team can improve their maturity level. Implementing anomaly detection techniques enables you to: 1. Proactively identify failures before they disrupt services 2. Speed up causal analysis 3. Reduce the time to restore services 4. Improve reliability via ML capabilities
The Cisco Observability Platform can be used for monitoring and implementing anomaly detection in the use cases we discussed in this post.
Learn more about the latest trends and articles on observability, DevOps, and monitoring with the resources below.
Resources:
Hub: Cisco Full-Stack Observability Hub
Documentation: Cisco Observability Platform Anomaly Detection Configuration API
Documentation: Cisco Observability Platform Health Rules Schema Introduction