NSO supports replication of the CDB configuration as well as of the operational data kept in CDB. The replication architecture is that of one active primary and a number of passive secondaries.
A group of NSO hosts consisting of a primary, and one or more secondaries, is referred to as an HA group (and sometimes as an HA cluster - however this is completely independent and separate from the Layered Service Architecture cluster feature.
All configuration write operations must occur at the primary and
NSO
will automatically distribute the configuration updates to the set
of live secondaries. Operational data in CDB may be replicated or not
based on the tailf:persistent statement in the data
model.
All write operations for replicated operational data must also occur
at the primary, with the updates distributed to the live secondaries,
whereas non-replicated operational data can also be written on the
secondaries.
As of NSO 5.4, NSO has built capabilities for defining HA group members, managing assignment of roles, handling failover etc. Alternatively, an external HA framework can be used. If so, NSO built-in HA must be disabled. The concepts described in the following sections applies both for NSO built-in HA and external HA framework.
Replication is supported in several different architectural setups. For example two-node active/standby designs as well as multi-node clusters with runtime software upgrade.
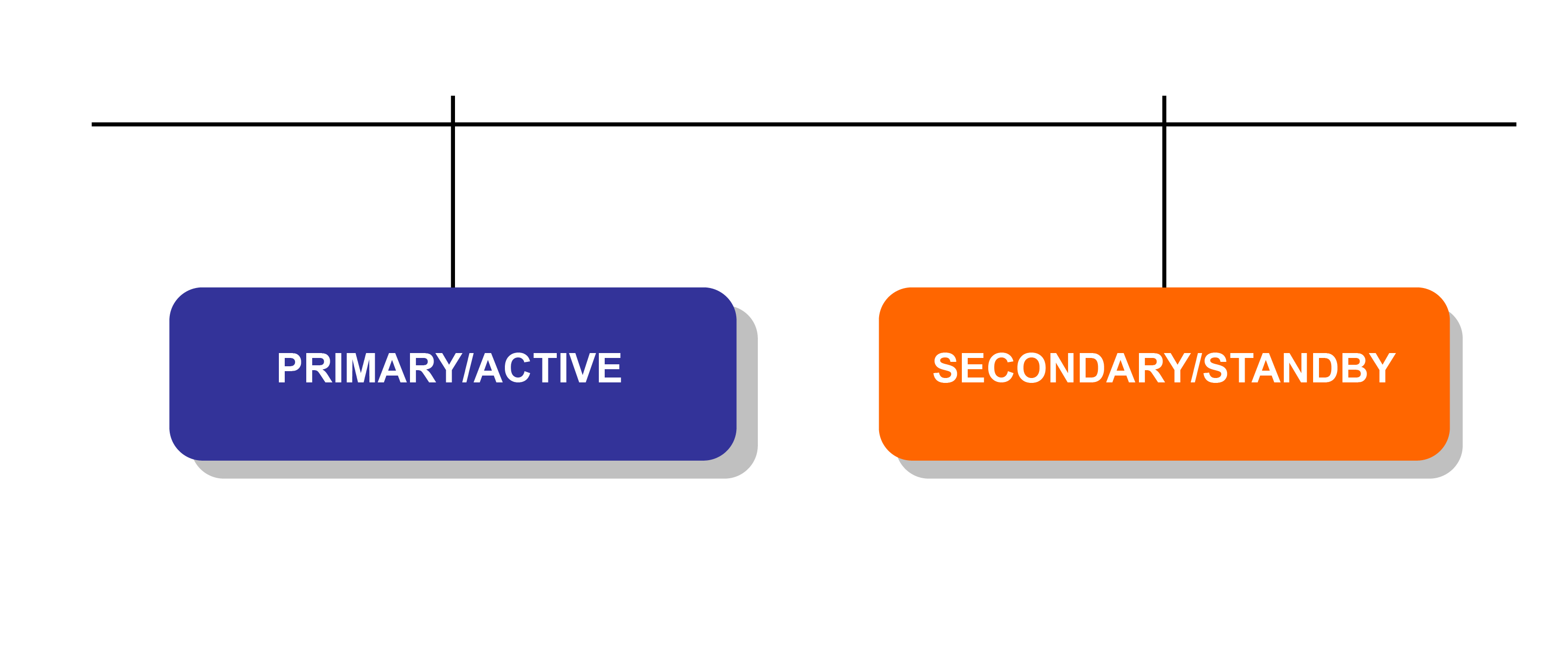 |
Primary - secondary configuration
 |
One primary - several secondaries
Furthermore it is assumed that the entire cluster configuration is equal on all hosts in the cluster. This means that node specific configuration must be kept in different node specific subtrees, for example as in Example 2, “A data model divided into common and node specific subtrees”.
container cfg {
container shared {
leaf dnsserver {
type inet:ipv4-address;
}
leaf defgw {
type inet:ipv4-address;
}
leaf token {
type AESCFB128EncryptedString;
}
...
}
container cluster {
list host {
key ip;
max-elements 8;
leaf ip {
type inet:ipv4-address;
}
...
}
}
}NSO has capabilities for managing HA groups out of the box as of version 5.4 and greater. The built-in capabilities allows administrators to:
-
Configure HA group members with IP addresses and default roles
-
Configure failover behavior
-
Configure start-up behavior
-
Configure HA group members with IP addresses and default roles
-
Assign roles, join HA group, enabled/disable built-in HA through actions
-
View the state of current HA setup
NSO Built-in HA is defined in tailf-ncs-high-availability.yang,
and is found under /high-availability/.
NSO built-in HA does not manage any virtual IP addresses, advertise any BGP routes or similar. This must be handled by an external package. Tailf-HCC 5.0 and greater has this functionality compatible with NSO Built-in HA.
Note: External HA frameworks are supported but should not be used in parallel with NSO built-in HA.
In order to use NSO built-in HA, HA must first be enabled
ncs.conf - See the section called “Mode of operation”
Note: if the package tailf-hcc with a version less than 5.0 is loaded, NSO built in HA will not function. These HCC versions may still be used but NSO Built-in HA will not function in parallel.
All HA group members are defined under
/high-availability/ha-node.
Each configured node must have a unique IP address configured, and
a unique HA Id. Additionally, nominal roles and fail-over settings
may be configured on a per node-basis.
The HA Node Id is a unique identifier used to identify NSO instances in a HA group. The HA Id of the local node - relevant amongst others when an action is called - is determined by matching configured HA node IP addresses against IP addresses assigned to the host machine of the NSO instance. As the HA Id is crucial to NSO HA, NSO built-in HA will not function if the local node cannot be identified.
In order to join a HA group, a shared secret must be
configured on the active primary and any prospective secondary. This
used for a CHAP-2 like authentication and is specified under
/high-availability/token/.
NSO can assume HA roles primary, secondary and none. Roles can be assigned directly through actions, or at startup or failover. See the section called “HA framework requirements” for the definition of these roles.
Note: NSO Built-in HA does not support relay-secondaries.
NSO Built-in HA differs between the concepts of nominal role and assigned role. Nominal-role is configuration data that applies when a NSO instance starts up and at failover. Assigned role is the role the NSO instance has been ordered to assume either by an action, or as result of startup or failover.
Failover may occur when a secondary node loses the connection to the primary node. A secondary may then take over the primary role. Failover behaviour is configurable and controlled by the parameters:
-
/high-availability/ha-node{id}/failover-master -
/high-availability/settings/enable-failover
For automatic failover to function,
/high-availability/settings/enable-failover
must be se to true.
It is then possible to enable at most one node with nominal
role secondary as
failover-primary, by setting the parameter
/high-availability/ha-node{id}/failover-master.
The failover works in both directions, if a nominal primary is currently
connected to the failover-primary as a secondary and loses the
connection, then it will attempt to take over as a primary.
Before failover happens, a failover-primary enabled secondary node may attempt to reconnect to the previous primary before assuming the primary role. This behaviour is configured by the parameters
-
/high-availability/settings/reconnect-attempts -
/high-availability/settings/reconnect-interval
denoting how many reconnect attempts will be made, and with which interval, respectively.
HA Members that are assigned as secondaries, but are neither
failover-primaries nor set with nominal-role primary, may
attempt to rejoin the HA group after losing connection to
primary. This is controlled by
/high-availability/settings/reconnect-slaves. If
this is true, secondary nodes will query the nodes configured
under /high-availability/ha-node for a NSO
instance that currently has the primary role. Any configured
nominal-roles will not be considered. If no primary node is
found, subsequent attempts to rejoin the HA setup will be
issued with an interval defined by
/high-availability/settings/reconnect-interval.
In case a net-split provokes a failover it is possible to end up in a situation with two masters, both nodes accepting writes. The masters are then not synchronized and will end up in split-brain. Once one of the masters join the other as a slave, the HA cluster is once again consistent but any out of sync changes will be overwritten.
To prevent split-brain to occur, NSO 5.7 or later comes with a rule-based algorithm. The algorithm is enabled by default, it can be disabled or changed from the parameters:
-
/high-availability/settings/consensus/enabled [true] -
/high-availability/settings/consensus/algorithm [ncs:rule-based]
The rule-based algorithm can be used in either of the two HA constellations:
-
Two nodes: one nominal master and one nominal slave configured as failover-master.
-
Three nodes: one nominal master, one nominal slave configured as failover-master and one perpetual slave.
On failover:
-
Failover-master: become master but enable read-only mode. Once the slave joins, disable read-only.
-
Nominal master: on loss of all slaves, change role to none. If one slave node is connected, stay master.
Note: In certain cases the rule-based consensus algorithm results in nodes being disconnected and will not automatically re-join the HA cluster, such as in the example above when the nominal master becomes none on loss of all slaves.
To restore the HA cluster one may need to manually invoke the /high-availability/be-slave-to action.
Note #2: In the case where the failover-master takes over as master, it will enable read-only mode, if no slave connects it will remain read-only. This is done to guarantee consistency.
Note #3: In a three-node cluster, when the nominal primary takes over as actual primary, it first enables read-only mode and stays in read-only mode until a secondary connects. This is done to guarantee consistency.
Read-write mode can manually be enabled from the /high-availability/read-only action with the parameter mode passed with value false.
Startup behaviour is defined by a combination of the
parameters
/high-availability/settings/start-up/assume-nominal-role
and
/high-availability/settings/start-up/join-ha
as well as the nodes nominal role:
assume-nominal-role
|
join-ha
|
nominal-role
|
behaviour
|
true
|
false
|
primary
|
Assume primary role. |
true
|
false
|
secondary
|
Attempt to connect as secondary to the node (if any) which has nominal-role primary. If this fails, make no retry attempts and assume none role. |
true
|
false
|
none
|
Assume none role |
false
|
true
|
primary
|
Attempt to join HA setup as secondary by querying
for current primary. Retries will be attempted. Retry
attempt interval is defined by
|
false
|
true
|
secondary
|
Attempt to join HA setup as secondary by querying
for current primary. Retries will be attempted. Retry
attempt interval is defined by
|
false
|
true
|
none
|
Assume none role. |
true
|
true
|
primary
|
Query HA setup once for a node with primary role. If found, attempt to connect as secondary to that node. If no current primary is found, assume primary role. |
true
|
true
|
secondary
|
Attempt to join HA setup as secondary by querying
for current primary. Retries will be attempted. Retry
attempt interval is defined by
|
true
|
true
|
none
|
Assume none role. |
false
|
false
|
-
|
Assume none role. |
NSO Built-in HA ca be controlled through a number of
actions. All actions are found under
/high-availability/. The available actions is
listed below:
Action
|
Description
|
be-master
|
Order the local node to assume ha role primary |
be-none
|
Order the local node to assume ha role none |
be-slave-to
|
Order the local node to connect as secondary to the
provided HA node. This is an asynchronous operation,
result can be found under
|
local-node-id
|
Identify the which of the nodes in
|
enable
|
Enable NSO built in HA and optionally assume a ha role according to /high-availability/settings/start-up/ parameters |
disable
|
Disable NSO built in HA and assume a ha role none |
The current state of NSO Built-in HA can be monitored by
observing
/high-availability/status/. Information can be found
about current active HA mode and current assigned role. For
nodes with active mode primary a list of connected nodes and their
source IP addresses is shown. For nodes with assigned role secondary
the latest result of the be-slave operation is listed. All NSO
built-in HA status information is non-replicated operational
data - the result here will differ between nodes connected in a
HA setup.
If an external HAFW is used, NSO only replicates the CDB data. NSO must be told by the HAFW which node should be primary and which nodes should be secondaries.
The HA framework must also detect when nodes fail and instruct NSO accordingly. If the primary node fails, the HAFW must elect one of the remaining secondaries and appoint it the new primary. The remaining secondaries must also be informed by the HAFW about the new primary situation.
NSO must be instructed through the
ncs.conf configuration file that it should
run in HA mode. The following configuration snippet enables HA
mode:
<ha>
<enabled>true</enabled>
<ip>0.0.0.0</ip>
<port>4570</port>
<extra-listen>
<ip>::</ip>
<port>4569</port>
</extra-listen>
<tick-timeout>PT20S</tick-timeout>
</ha>The IP address and the port above indicates which IP and
which port should be used for the communication between the HA
nodes. extra-listen
is an optional list
of ip:port pairs
which a HA primary also listens to
for secondary connections. For IPv6 addresses, the syntax [ip]:port may
be used. If the ":port" is omitted, port is used.
The tick-timeout
is a duration indicating how
often each secondary must send a tick message to the primary indicating
liveness. If the primary has not received a tick from a secondary
within 3 times the configured tick time, the secondary is considered
to be dead. Similarly, the primary sends tick messages to all the
secondaries. If a secondary has not received any tick messages from the
primary within the 3 times the timeout, the secondary will consider the
primary dead and report accordingly.
A HA node can be in one of three states:
NONE, SLAVE (secondary) or
MASTER (primary). Initially a node is in the
NONE state. This implies that the node
will read its configuration from CDB, stored locally on file.
Once the HA framework has decided whether the node should be a
secondary or a primary the HAFW must invoke either the
methods
Ha.beSlave(master) or
Ha.beMaster()
When a NSO HA node starts, it always starts up in mode
NONE. At this point there are no other nodes
connected. Each NSO node reads its configuration
data from the locally stored CDB and applications on or off the
node may connect to NSO and read the data they need.
Although write operations are allowed in the NONE
state it is highly discouraged to initiate southbound
communication unless necessary. A node in NONE state
should only be used to configure NSO itself or to do
maintenance such as upgrades. When in NONE state, some
features are disabled, including but not limited to:
-
commit queue
NSO scheduler
nano-service side effect queue
This is in order to avoid situations where multiple NSO nodes are trying to perform the same southbound operation simultaneously.
At some point, the HAFW will command some nodes to become secondary nodes of a named primary node. When this happens, each secondary node tracks changes and (logically or physically) copies all the data from the primary. Previous data at the secondary node is overwritten.
Note that the HAFW, by using NSO's start phases, can make
sure that NSO does not start its northbound interfaces (NETCONF,
CLI, ...) until the HAFW has decided what type of node it
is. Furthermore once a node has been set to the SLAVE state,
it is not possible to initiate new write transactions towards the node.
It is thus never possible for an agent to write directly into a
secondary node.
Once a node is returned either to the NONE state or to
the MASTER state, write transactions can once again be initiated
towards the node.
The HAFW may command a secondary node to become primary at any time. The secondary node already has up-to-date data, so it simply stops receiving updates from the previous primary. Presumably, the HAFW also commands the primary node to become a secondary node, or takes it down or handles the situation somehow. If it has crashed, the HAFW tells the secondary to become primary, restarts the necessary services on the previous primary node and gives it an appropriate role, such as secondary. This is outside the scope of NSO.
Each of the primary and secondary nodes have the same set of all callpoints and validation points locally on each node. The start sequence has to make sure the corresponding daemons are started before the HAFW starts directing secondary nodes to the primary, and before replication starts. The associated callbacks will however only be executed at the primary. If e.g. the validation executing at the primary needs to read data which is not stored in the configuration and only available on another node, the validation code must perform any needed RPC calls.
If the order from the HAFW is to become primary, the node
will start to listen for incoming secondaries at the ip:port
configured under /ncs-config/ha. The secondaries TCP connect
to the primary and this socket is used by NSO to distribute the
replicated data.
If the order is to be a secondary, the node will contact the primary and possibly copy the entire configuration from the primary. This copy is not performed if the primary and secondary decide that they have the same version of the CDB database loaded, in which case nothing needs to be copied. This mechanism is implemented by use of a unique token, the "transaction id" - it contains the node id of the node that generated it and and a time stamp, but is effectively "opaque".
This transaction id is generated by the cluster primary each time a configuration change is committed, and all nodes write the same transaction id into their copy of the committed configuration. If the primary dies, and one of the remaining secondaries is appointed new primary, the other secondaries must be told to connect to the new primary. They will compare their last transaction id to the one from the newly appointed primary. If they are the same, no CDB copy occurs. This will be the case unless a configuration change has sneaked in, since both the new primary and the remaining secondaries will still have the last transaction id generated by the old primary - the new primary will not generate a new transaction id until a new configuration change is committed. The same mechanism works if a secondary node is simply restarted. In fact no cluster reconfiguration will lead to a CDB copy unless the configuration has been changed in between.
Northbound agents should run on the primary, it is not possible for an agent to commit write operations at a secondary node.
When an agent commits its CDB data, CDB will stream the committed data out to all registered secondaries. If a secondary dies during the commit, nothing will happen, the commit will succeed anyway. When and if the secondary reconnects to the cluster, the secondary will have to copy the entire configuration. All data on the HA sockets between NSO nodes only go in the direction from the primary to the secondaries. A secondary which isn't reading its data will eventually lead to a situation with full TCP buffers at the primary. In principle it is the responsibility of HAFW to discover this situation and notify the primary NSO about the hanging secondary. However if 3 times the tick timeout is exceeded, NSO will itself consider the node dead and notify the HAFW. The default value for tick timeout is 20 seconds.
The primary node holds the active copy of the entire configuration data in CDB. All configuration data has to be stored in CDB for replication to work. At a secondary node, any request to read will be serviced while write requests will be refused. Thus, CDB subscription code works the same regardless of whether the CDB client is running at the primary or at any of the secondaries. Once a secondary has received the updates associated to a commit at the primary, all CDB subscribers at the secondary will be duly notified about any changes using the normal CDB subscription mechanism.
If the system has been setup to subscribe for NETCONF notifications, the secondaries will have all subscriptions as configured in the system, but the subscription will be idle. All NETCONF notifications are handled by the primary, and once the notifications get written into stable storage (CDB) at the primary, the list of received notifications will be replicated to all secondaries.
We specify in ncs.conf which IP
address the primary should bind for incoming secondaries. If we choose
the default value 0.0.0.0 it is the responsibility of
the application to ensure that connection requests only arrive
from acceptable trusted sources through some means of
firewalling.
A cluster is also protected by a token, a secret string only
known to the application. The Ha.connect() method
must be given the token.
A secondary node that connects to a primary node negotiates with the
primary using a CHAP-2 like protocol, thus both the primary and the
secondary are ensured that the other end has the same token without
ever revealing their own token. The token is never sent in clear
text over the network. This mechanism ensures that a connection
from a NSO secondary to a primary can only succeed if they both have
the same token.
It is indeed possible to store the token itself in CDB, thus
an application can initially read the token from the local CDB
data, and then use that token in
.
the constructor for the Ha
class.
In this case it may very
well be a good idea to have the token stored in CDB be of type
tailf:aes-256-cfb-128-encrypted-string.
If the actual CDB data that is sent on the wire between cluster nodes is sensitive, and the network is untrusted, the recommendation is to use IPSec between the nodes. An alternative option is to decide exactly which configuration data is sensitive and then use the tailf:aes-256-cfb-128-encrypted-string type for that data. If the configuration data is of type tailf:aes-256-cfb-128-encrypted-string the encrypted data will be sent on the wire in update messages from the primary to the secondaries.
There are two APIs used by the HA framework to control the replication aspects of NSO. First there exists a synchronous API used to tell NSO what to do, secondly the application may create a notifications socket and subscribe to HA related events where NSO notifies the application on certain HA related events such as the loss of the primary etc. The HA related notifications sent by NSO are crucial to how to program the HA framework.
The HA related classes reside in the com.tailf.ha package. See Javadocs for reference. The HA notifications related classes reside in the com.tailf.notif package, See Javadocs for reference.
The configuration parameter
/ncs-cfg/ha/tick-timeout is by default set to 20
seconds. This means that every 20 seconds each secondary will send a
tick message on the socket leading to the primary. Similarly, the
primary will send a tick message every 20 seconds on every secondary
socket.
This aliveness detection mechanism is necessary for NSO.
If a socket gets closed all is well, NSO will cleanup and notify
the application accordingly using the notifications API. However,
if a remote node freezes, the socket will not get properly closed
at the other end. NSO will distribute update data from the
primary to the secondaries. If a remote node is not reading the data,
TCP buffer will get full and NSO will have to start to buffer
the data. NSO will buffer data for at most tickTime
times 3 time units. If a tick has not been received
from a remote node within that time, the node will be considered
dead. NSO will report accordingly over the notifications socket
and either remove the hanging secondary or, if it is a secondary that
loose contact with the primary, go into the initial NONE
state.
If the HAFW can be really trusted, it is possible to set
this timeout to PT0S, i.e zero, in which case
the entire dead-node-detection mechanism in NSO is
disabled.
The normal setup of a NSO HA cluster is to have all secondaries connected directly to the primary. This is a configuration that is both conceptually simple and reasonably straightforward to manage for the HAFW. In some scenarios, in particular a cluster with multiple secondaries at a location that is network-wise distant from the primary, it can however be sub-optimal, since the replicated data will be sent to each remote secondary individually over a potentially low-bandwidth network connection.
To make this case more efficient, we can instruct a secondary to
be a relay for other secondaries, by invoking the Ha.beRelay() method.
This will make the secondary start listening on the IP address and port
configured for HA in ncs.conf, and handle connections
from other secondaries in the same manner as the cluster primary does. The
initial CDB copy (if needed) to a new secondary will be done from the
relay secondary, and when the relay secondary receives CDB data for
replication from its primary, it will distribute the data to all its
connected secondaries in addition to updating its own CDB copy.
To instruct a node to become a secondary connected to a relay
secondary, we use the Ha.beSlave() method as
usual, but pass the node information for the relay secondary instead of
the node information for the primary. I.e. the "sub-secondary" will in
effect consider the relay secondary as its primary. To instruct a relay
secondary to stop being a relay, we can invoke the Ha.beSlave()
method with the same parameters as in the original
call. This is a no-op for a "normal" secondary, but it will cause a
relay secondary to stop listening for secondary connections, and disconnect
any already connected "sub-secondaries".
This setup requires special consideration by the HAFW. Instead of just telling each secondary to connect to the primary independently, it must setup the secondaries that are intended to be relays, and tell them to become relays, before telling the "sub-secondaries" to connect to the relay secondaries. Consider the case of a primary M and a secondary S0 in one location, and two secondaries S1 and S2 in a remote location, where we want S1 to act as relay for S2. The setup of the cluster then needs to follow this procedure:
-
Tell M to be primary.
-
Tell S0 and S1 to be secondary with M as primary.
-
Tell S1 to be relay.
-
Tell S2 to be secondary with S1 as primary.
Conversely, the handling of network outages and node failures
must also take the relay secondary setup into account. For example, if a
relay secondary loses contact with its primary, it will transition to the
NONE state just like any other secondary, and it will then
disconnect its "sub-secondaries" which will cause those to transition to
NONE too, since they lost contact with "their" primary. Or
if a relay secondary dies in a way that is detected by its
"sub-secondaries",
they will also transition to NONE. Thus in the example
above, S1 and S2 needs to be handled differently. E.g. if S2 dies,
the HAFW probably won't take any action, but if S1 dies, it makes
sense to instruct S2 to be a secondary of M instead (and when S1 comes
back, perhaps tell S2 to be a relay and S1 to be a secondary of
S2).
Besides the use of Ha.beRelay(), the API is mostly
unchanged when using relay secondaries. The HA event notifications
reporting the arrival or the death of a secondary are still generated
only by the "real" cluster primary. If the Ha.HaStatus() method
is used towards a relay secondary, it will report the node state as
SLAVE_RELAY rather than just SLAVE, and the
array of nodes will have its primary as the first element (same as
for a "normal" secondary), followed by its "sub-secondaries"
(if any).
When HA is enabled in ncs.conf CDB
automatically replicates data written on the primary to the
connected secondary nodes. Replication is done on a per-transaction
basis to all the secondaries in parallel. It can be configured to be
done asynchronously (best performance) or synchronously in step
with the transaction (most secure). When NSO is in secondary mode
the northbound APIs are in read-only mode, that is the
configuration can not be changed on a secondary other than through
replication updates from the primary. It is still possible to read
from for example NETCONF or CLI (if they are enabled) on a
secondary. CDB subscriptions works as usual.
When NSO is in the NONE
state CDB is unlocked and it behaves as when NSO is not in HA
mode at all.
Operational data is always replicated on all secondaries similar to how
configuration data is replicated.
Operational data is always replicated asynchronously, regardless of
the /ncs-config/cdb/operational/replication setting.